
ML Tracking: Experiment, Model Metadata, and Management
Experiment tracking, model metadata storage, and management are essential practices in the machine learning (ML) lifecycle. They work together to provide a comprehensive view of your model development process, enabling you to:
- Track and analyze experiments: Record every aspect of your experiments, including hyperparameters, data versions, metrics, and also code commits.
- Reproduce and compare models: Easily recreate successful experiments and also compare different models based on their metadata and also performance.
- Manage model lifecycles: Control the deployment, versioning, and also monitoring of models throughout their journey from development to production.
ML Tracking: Efficient Experiments, Metadata, Management:
- Increased efficiency: Streamline your ML workflow by reducing manual tracking and also simplifying collaboration.
- Improved reproducibility: Ensure consistent results and also facilitate accurate comparisons between experiments.
- Enhanced model governance: Gain better control and oversight over your ML models, ensuring compliance and also responsible AI practices.
- Faster iteration: Accelerate your path to optimal models by learning from past experiments and also making informed decisions.
- Reduced risk: Mitigate the risk of deploying unreliable models by identifying issues early in the development process.
Tracking, model storage, and management: core features
- Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and also artifacts.
- Comparison and also analysis of different runs.
- Versioning and also lineage tracking of experiments.
- Collaboration tools for sharing and also discussing results.
- Model Metadata Storage:
- Centralized repository for all model-related information.
- Metadata schema for storing key attributes of models, including training data, algorithms, and also performance metrics.
- Versioning and also access control are used for managing different model versions.
- Integration with other ML tools and also platforms.
- Management:
- Model registry for registering, tagging, and also searching models.
- Deployment pipelines for streamlining model deployment to production.
- Monitoring and alerting for tracking model performance in production.
- Governance tools for enforcing policies and also managing model access.
By implementing these practices, you can unlock the full potential of your ML projects and achieve faster, more reliable, and more impactful results.
Tools for tracking, storing, and managing model metadata
- MLflow Tracking
- Weights and Biases
- Neptune
- TensorBoard
- Comet ml
- Sacred
- Valohai
- ClearML
- Pachyderm
- CML (Coiled Machine Learning)
1. MLflow Tracking: Unified ML Lifecycle Optimization
MLflow Tracking stands as a robust, open-source platform meticulously crafted to optimize the entire machine learning (ML) lifecycle. This comprehensive solution seamlessly integrates Experiment tracking, model metadata storage, and also management, offering a unified hub for streamlined processes. At its core, MLflow Tracking establishes a centralized repository, systematically logging metrics, artifacts, and also parameters. This pivotal feature empowers users to effortlessly compare and also track diverse runs within their ML experiments. The platform’s versatility shines through its smooth integration with various tools, ensuring a seamless transition between critical stages, including model training, deployment, and also serving.
Key Capabilities: MLflow Tracking for Unified ML Lifecycle
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: MLflow Tracking allows users to log and track experiment parameters, metrics, and also artifacts, providing a comprehensive view of the experiment’s progress.
- Comparison and analysis of different runs: MLflow facilitates the comparison of different runs through its tracking UI, enabling users to analyze and also contrast experiment results.
- Versioning and lineage tracking of experiments: MLflow supports the versioning of models and tracks the lineage of each run, ensuring reproducibility and also traceability of experiments.
- Collaboration tools for sharing and discussing results: MLflow provides a platform for collaborative work by allowing users to share experiment results and also discuss findings.
Model Metadata Storage:
- Centralized repository for all model-related information: MLflow serves as a centralized repository for storing comprehensive model-related information, including parameters, metrics, and also artifacts.
- Metadata schema for storing key attributes of models: MLflow defines a metadata schema to store critical attributes of models, such as training data, algorithms, and performance metrics.
- Versioning and access control: MLflow incorporates versioning and also access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: MLflow is designed to integrate seamlessly with various ML tools and also platforms, ensuring interoperability.
Management:
- Model registry: MLflow offers a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: MLflow provides deployment pipelines to streamline the deployment of models to production environments.
- Monitoring and alerting: MLflow includes monitoring and also alerting features to track and alert on model performance in production.
- Governance tools: MLflow incorporates governance tools to enforce policies and also manage model access.
How it works: MLflow Tracking operates as a cohesive and user-friendly hub, providing a unified space for logging and also monitoring key aspects of ML experiments. Metrics, parameters, and also artifacts are captured with precision, enabling users to effortlessly trace the evolution of models across different runs. Facilitating collaboration, MLflow offers a consistent interface, promoting teamwork among users. Its adaptability is underscored by compatibility with a multitude of machine-learning libraries and also frameworks. This versatility positions MLflow Tracking as an invaluable asset for both research-oriented exploration and production-centric ML workflows, ensuring a holistic and efficient approach to managing the complete ML lifecycle.
2. Enhance ML Experiment Management with Weights & Biases
Weights & Biases stands as a cloud-based powerhouse, meticulously crafted to elevate the tracking and visualization of machine learning experiments. This innovative platform boasts a user-friendly interface that empowers users to seamlessly visualize metrics, compare experiment runs, and foster collaboration on ML projects. Going beyond mere visualization, it autonomously tracks experiment data, providing a sophisticated arsenal of tools for versioning models, annotation, and effortless sharing.
Key Capabilities: Empowering ML with Weights & Biases:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Weights and Biases enable the logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Weights and Biases support comparing and analyzing different experiment runs through their visualization tools.
- Versioning and lineage tracking of experiments: Weights and Biases provide versioning and lineage tracking, ensuring experiment reproducibility and traceability.
- Collaboration tools for sharing and discussing results: Weights and Biases offer collaboration tools for sharing and discussing experiment results among team members.
Model Metadata Storage:
- Centralized repository for all model-related information: Weights and Biases serve as a centralized repository for storing comprehensive model-related information, fostering organization and accessibility.
- Metadata schema for storing key attributes of models: Weights and Biases define a metadata schema to capture key attributes of models, facilitating organized model information storage.
- Versioning and access control: Weights and Biases implement versioning and access control mechanisms for managing different model versions securely.
- Integration with other ML tools and platforms: Weights and Biases seamlessly integrate with various ML tools and platforms to enhance collaboration and interoperability.
Management:
- Model registry: Weights and Biases offer a model registry for registering, tagging, and searching models, simplifying model management.
- Deployment pipelines: Weights and Biases support deployment pipelines to streamline the deployment of models to production environments.
- Monitoring and alerting: Weights and Biases include monitoring and alerting features to track and alert on model performance in production.
- Governance tools: Weights and Biases incorporate governance tools to enforce policies and manage access to models.
How it works: Weights & Biases redefines the ML experimentation landscape by automating the tracking of indispensable data. The platform’s brilliance unfolds through its intuitive dashboard, a visual playground where metrics come to life. This dashboard not only simplifies complex data but also becomes a gateway for users to gain profound insights into the performance nuances of diverse models and experiments. Collaboration is the heartbeat of Weights and biases, made evident through advanced features such as model versioning and annotation. These collaborative elements transform Weights and biases into indispensable assets for teams immersed in the intricacies of complex ML projects.
In essence, Weights & Biases stands as a beacon, not just in visualizing data but in fostering collaboration and automating essential tracking processes. As teams embark on the journey of machine learning endeavors, this platform emerges as a stalwart companion, offering insights, efficiency, and a collaborative ecosystem that propels ML projects to new heights of success.
3. Neptune: Empowering ML Reproducibility & Transparency
Neptune stands out as an open-source ML experiment tracking platform, placing a paramount focus on bolstering reproducibility and preserving data provenance. With meticulous attention to detail, Neptune adeptly tracks experiment runs, logs crucial metrics, and captures hyperparameters. This platform goes beyond mere tracking, offering powerful visualization tools that facilitate comprehensive analysis. The core mission of Neptune is to instill transparency and reproducibility in machine learning workflows, achieved by placing a strong emphasis on capturing the complete environment and dependencies for each run.
Neptune: Unveiling Key Capabilities for Seamless Innovation:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Neptune facilitates the logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Neptune supports the comparison and analysis of different experiment runs through its tracking and visualization tools.
- Versioning and lineage tracking of experiments: Neptune provides versioning and lineage tracking capabilities, ensuring experiment reproducibility and traceability.
- Collaboration tools for sharing and discussing results: Neptune offers collaboration tools, allowing users to share and discuss experiment results within a team.
Model Metadata Storage:
- Centralized repository for all model-related information: Neptune acts as a centralized repository for storing comprehensive model-related information, promoting easy access and organization.
- Metadata schema for storing key attributes of models: Neptune defines a metadata schema for storing key attributes of models, enhancing model information management.
- Versioning and access control: Neptune implements versioning and also access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: Neptune seamlessly integrates with various ML tools and also platforms, promoting interoperability.
Management:
- Model registry: Neptune provides a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: Neptune supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: Neptune includes monitoring and alerting features to track and also alert on model performance in production.
- Governance tools: Neptune incorporates governance tools for enforcing policies and also managing access to models.
How it Works: Neptune simplifies the intricate process of experiment tracking by providing a holistic environment that seamlessly integrates logging and visualization of metrics. By comprehensively capturing the entire environment and dependencies, Neptune significantly enhances the reproducibility of ML experiments. This emphasis on provenance, or the origin and history of data, makes Neptune an invaluable asset for research and development teams committed to fostering transparent and reproducible machine learning workflows.
4. TensorBoard: Streamlining ML Insights with Visual Power
TensorBoard, a powerful visualization tool crafted by TensorFlow, serves as an indispensable asset for effectively presenting metrics and model structures in the realm of machine learning. Tailored to streamline the comprehension of complex ML data, TensorBoard offers interactive dashboards that empower users to delve into training progress, scrutinize loss functions, and navigate model parameters seamlessly. This tool stands out for its user-friendly interface and adaptability, providing a versatile solution for researchers and engineers alike.
Unlocking Insights: Key Capabilities of TensorBoard:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: TensorBoard enables the logging and visualization of hyperparameters, metrics, and also artifacts during TensorFlow experiments.
- Comparison and analysis of different runs: TensorBoard supports the comparison and also analysis of different experiment runs through its visualization tools.
- Versioning and lineage tracking of experiments: TensorBoard provides limited versioning and also lineage tracking capabilities, mainly within the TensorFlow ecosystem.
- Collaboration tools for sharing and discussing results: TensorBoard may require additional tools for collaboration but integrates well within the TensorFlow framework.
Model Metadata Storage:
- Centralized repository for all model-related information: TensorBoard relies on TensorFlow’s model-saving mechanisms and may benefit from additional tools for a centralized repository.
- The metadata schema for storing key attributes of models: TensorBoard utilizes TensorFlow’s model-saving mechanisms, contributing to metadata storage.
- Versioning and access control: TensorBoard’s versioning and also access control may be dependent on TensorFlow’s capabilities.
Management:
- Model registry: TensorBoard may utilize the TensorFlow Model Registry or other external tools for model registration and management.
- Deployment pipelines: TensorBoard integrates with TensorFlow Serving for deployment pipelines.
- Monitoring and alerting: TensorBoard may require additional tools for comprehensive monitoring and also alerting.
- Governance tools: Governance tools for TensorBoard are typically managed through TensorFlow’s broader ecosystem.
How It Works: TensorBoard simplifies the visualization of intricate ML data through its intuitive dashboards, fostering a user experience that prioritizes ease of use. As users embark on tracking training progress, TensorBoard ensures a comprehensive overview, allowing for nuanced insights into the evolving dynamics of machine learning models. The platform’s integration with TensorFlow and compatibility with various frameworks amplify its versatility. Users can seamlessly visualize experiment data directly within the platform, making TensorBoard a go-to choice for those seeking a streamlined approach to comprehending and optimizing their ML models. With TensorBoard, the journey of understanding and refining machine learning models becomes not only accessible but also efficient, catering to the diverse needs of both seasoned researchers and budding engineers.
TensorBoard, a sophisticated and accessible visualization tool, provides a user-friendly interface for exploring metrics and models. In the dynamic field of machine learning, TensorBoard excels in the in-depth exploration of evolving metrics and structures. TensorBoard, seamlessly integrated with TensorFlow, stands as an essential companion for researchers and engineers. Navigating the complexities of ML model development is made easier with TensorBoard’s broad framework compatibility.
5. Comet ML: Elevate Your ML Workflow with Precision
Comet ml is an advanced cloud-based platform meticulously crafted to efficiently track, optimize, and manage machine learning experiments. Specializing in experiment tracking, hyperparameter tuning, and model management, Comet ml is a comprehensive solution for teams navigating the complexities of iterative and collaborative ML projects. This versatile platform excels in facilitating the logging of experiment data, metrics visualization, and hyperparameter optimization through cutting-edge techniques, including Bayesian and grid search methodologies. Additionally, Comet ml is equipped with robust tools to support model versioning, deployment, and monitoring, providing a holistic environment for seamless ML workflow management.
Elevate Workflows with Comet ml’s Key Capabilities:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Comet ml allows logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Comet ml supports comparing and analyzing different experiment runs through its tracking and visualization tools.
- Versioning and lineage tracking of experiments: Comet ml provides versioning and lineage tracking, ensuring reproducibility and experiment traceability.
- Collaboration tools for sharing and discussing results: Comet ml offers collaboration tools for sharing and discussing experiment results, enhancing team communication.
Model Metadata Storage:
- Centralized repository for all model-related information: Comet ml acts as a centralized repository for storing comprehensive model-related information, promoting easy access and organization.
- Metadata schema for storing key attributes of models: Comet ml defines a metadata schema for storing key attributes of models, contributing to effective model information management.
- Versioning and access control: Comet ml implements versioning and access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: Comet ml integrates seamlessly with various ML tools and platforms, ensuring interoperability.
Management:
- Model registry: Comet ml provides a model registry for registering, tagging, and searching models, simplifying model management.
- Deployment pipelines: Comet ml supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: Comet ml includes monitoring and alerting features to track and alert on model performance in production.
- Governance tools: Comet ml incorporates governance tools for enforcing policies and managing access to models.
How It Works: Comet ml simplifies and enhances the tracking and optimization of machine learning experiments through its suite of sophisticated features. Users can effortlessly log crucial experiment data, gaining valuable insights for informed decision-making. The platform’s intuitive visualization tools empower users to explore and comprehend complex metrics effectively. Comet ml takes optimization to the next level by offering advanced hyperparameter tuning methods, such as Bayesian and grid search, ensuring that models are finely tuned for optimal performance.
6. Sacred: Streamlining ML Experiments for Reproducibility
Sacred, a Python library, is purpose-built for orchestrating and overseeing machine learning (ML) experiments. It establishes a versatile framework empowering users to structure and manage experiment configurations easily. Sacred’s proficiency in simplifying the critical aspect of experiment reproducibility sets it apart. It achieves this by adeptly managing dependencies and capturing the complete environment for each run, ensuring consistent outcomes across diverse experiment iterations.
Sacred Unleashed: Exploring Essential Key Capabilities:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Sacred enables logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Sacred supports the comparison and analysis of different experiment runs through its tracking tools.
- Versioning and lineage tracking of experiments: Sacred provides versioning and lineage tracking features for experiment reproducibility and traceability.
- Collaboration tools for sharing and discussing results: Sacred may require additional tools for collaboration but integrates well within its framework.
Model Metadata Storage:
- Centralized repository for all model-related information: Sacred may rely on external tools for a centralized repository or use its database for model-related information.
- Metadata schema for storing key attributes of models: Sacred defines a metadata schema for storing key attributes of models within its database.
- Versioning and access control: Sacred implements versioning and access control mechanisms, ensuring secure management of different model versions.
- Integration with other ML tools and platforms: Sacred integrates with various ML tools and platforms for enhanced interoperability.
Management:
- Model registry: Sacred may utilize external model registries or its internal mechanisms for registering, tagging, and searching models.
- Deployment pipelines: Sacred integrates with deployment pipelines for streamlined model deployment to production.
- Monitoring and alerting: Sacred may require additional tools for comprehensive monitoring and alerting.
- Governance tools: Governance tools for Sacred are typically managed within its ecosystem.
How It Works: Sacred functions as a comprehensive framework designed to streamline the organization and management of machine learning experiments. Users initiate the process by defining experiment configurations, a task seamlessly facilitated by Sacred. Once configured, Sacred assumes responsibility for diligently tracking the execution of these experiments. The library’s paramount focus on reproducibility is underscored by its ability to adeptly manage dependencies and comprehensively capture the entire environment for each run. This proficiency makes Sacred an exceptional choice for researchers and developers striving to uphold uniformity and reliability across a spectrum of experiment runs.
7. Valohai: Seamless ML Lifecycle from Dev to Production
Valohai stands out as a comprehensive platform meticulously crafted for the creation, supervision, and deployment of machine learning models within production environments. This all-inclusive solution boasts features encompassing code versioning, model training, deployment processes, and real-time monitoring capabilities. Offering a secure and scalable environment, Valohai seamlessly guides ML projects through every phase, ensuring a smooth transition from development to the demanding landscape of production.
Maximizing Efficiency: Valohai’s Key Capabilities:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Valohai allows logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Valohai supports comparing and analyzing different experiment runs through its tracking and visualization tools.
- Versioning and lineage tracking of experiments: Valohai provides versioning and lineage tracking features, ensuring reproducibility and traceability of experiments.
- Collaboration tools for sharing and discussing results: Valohai offers collaboration tools for sharing and discussing experiment results, facilitating team communication.
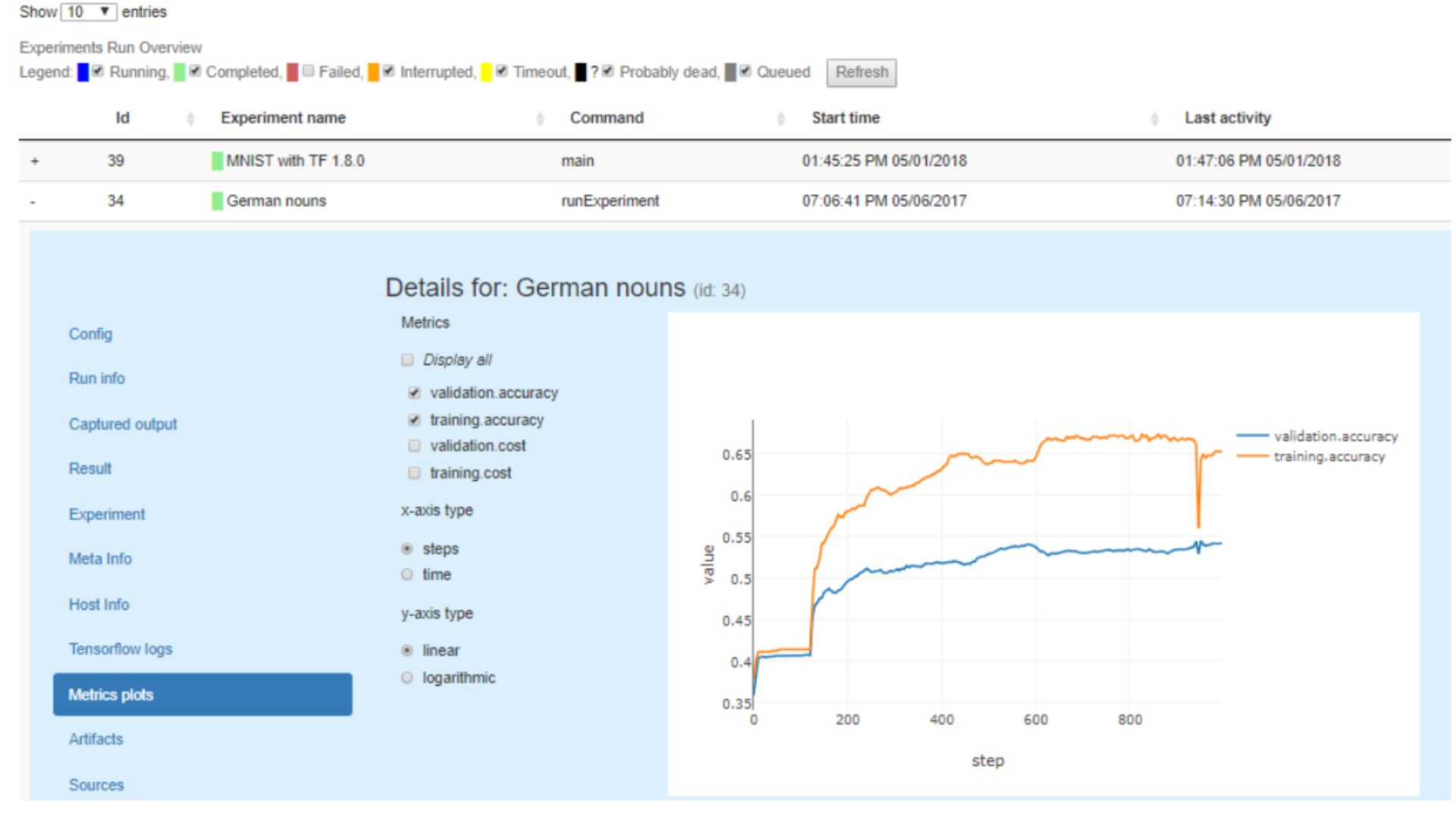
Model Metadata Storage:
- Centralized repository for all model-related information: Valohai acts as a centralized repository for storing comprehensive model-related information, promoting organization and easy access.
- Metadata schema for storing key attributes of models: Valohai defines a metadata schema for storing key attributes of models, contributing to effective model information management.
- Versioning and access control: Valohai implements versioning and access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: Valohai integrates seamlessly with various ML tools and platforms, ensuring interoperability.
Management:
- Model registry: Valohai provides a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: Valohai supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: Valohai includes monitoring and alerting features to track and also alert on model performance in production.
- Governance tools: Valohai incorporates governance tools for enforcing policies and also managing access to models.
How It Works: Valohai operates as a streamlined conductor orchestrating the various stages of the machine learning lifecycle. Users are empowered to effortlessly navigate through code versioning, model training, deployment procedures, and also ongoing performance monitoring. This unified platform provides a centralized hub for managing the intricate processes involved in ML model development. As organizations grapple with the complex landscape of machine learning projects, Valohai’s steadfast focus on security and also scalability emerges as a pivotal strength. Its robust architecture becomes an indispensable asset for enterprises striving to efficiently manage and also deploy machine learning initiatives, reinforcing its status as a stalwart choice in the ever-evolving realm of artificial intelligence.
8. ClearML: Elevating ML with Data Lineage and Collaboration
ClearML, an open-source platform, significantly emphasizes data lineage and collaboration to streamline the entire machine learning (ML) lifecycle. It is meticulously designed to track experiment data, models, and deployments, setting itself apart by prioritizing data provenance—capturing the origin and intricate relationships between diverse artifacts.
Key Capabilities: ClearML Unleashes Powerful Features:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: ClearML allows logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: ClearML supports the comparison and analysis of different experiment runs through its tracking and also visualization tools.
- Versioning and lineage tracking of experiments: ClearML provides versioning and lineage tracking features, ensuring experiment reproducibility and also traceability.
- Collaboration tools for sharing and discussing results: ClearML offers collaboration tools for sharing and also discussing experiment results, enhancing team communication.
Model Metadata Storage:
- Centralized repository for all model-related information: ClearML acts as a centralized repository for storing comprehensive model-related information, promoting organization and also easy access.
- Metadata schema for storing key attributes of models: ClearML defines a metadata schema for storing key attributes of models, contributing to effective model information management.
- Versioning and access control: ClearML implements versioning and also access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: ClearML integrates seamlessly with various ML tools and also platforms, ensuring interoperability.
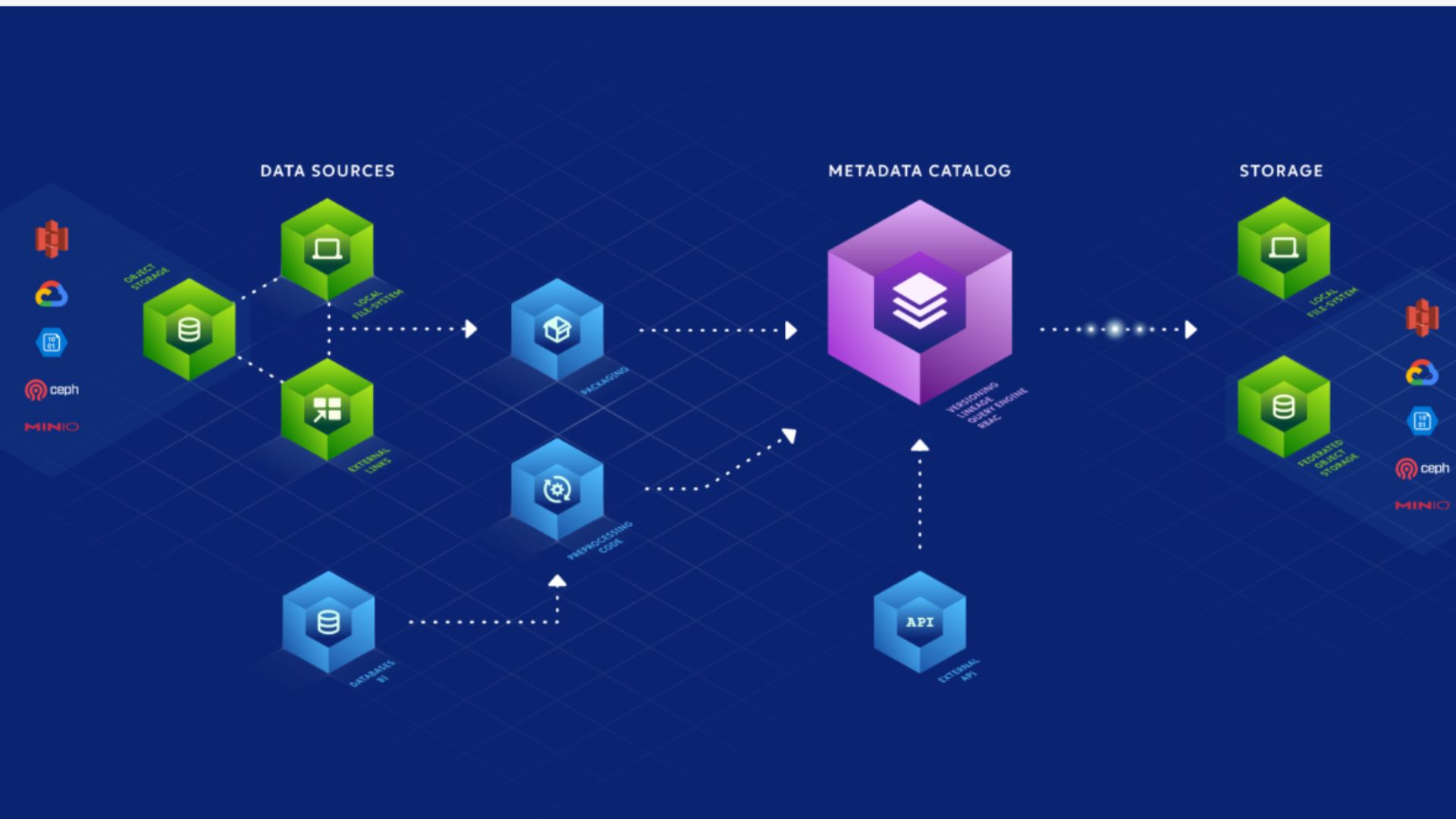
Management:
- Model registry: ClearML provides a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: ClearML supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: ClearML includes monitoring and alerting features to track and also alert on model performance in production.
- Governance tools: ClearML incorporates governance tools for enforcing policies and managing access to models.
How It Works: ClearML simplifies ML experiment tracking and management, offering a dedicated platform focused on data lineage. Users effortlessly track experiment data, model iterations, and deployments, enhancing their overall experience. ClearML provides a nuanced understanding of relationships between distinct artifacts, improving comprehension and preservation. Its profound emphasis on data provenance makes ClearML invaluable, especially for organizations prioritizing lineage understanding.
In the realm of SEO and readability, ClearML emerges as a standout solution for organizations seeking transparency and also collaboration in their ML workflows. By offering an open-source platform that excels in data lineage, ClearML ensures a smooth and also comprehensible experience for users. The emphasis on data provenance enhances the platform’s credibility, making it a compelling choice for those who prioritize the integrity and understanding of their machine-learning processes. With ClearML, organizations can navigate the complexities of the ML lifecycle with clarity and confidence, fostering a collaborative and also data-centric approach to experimentation and deployment.
9.Pachyderm: ML Data Pipelines with Kubernetes Integration
Pachyderm stands out as an exceptional data pipeline system tailored for machine learning (ML), seamlessly integrating with Kubernetes to streamline the management and also execution of data processing workflows. This platform offers a robust framework, empowering users to define and also execute data pipelines within a containerized environment. Its primary focus is on simplifying data management for ML projects by facilitating versioning, ensuring reproducibility, and enabling seamless scaling.
Data Evolution: Unveiling Pachyderm’s Key Capabilities:
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: Pachyderm enables logging and visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: Pachyderm supports the comparison and analysis of different experiment runs through its tracking and also visualization tools.
- Versioning and lineage tracking of experiments: Pachyderm provides versioning and lineage tracking features, ensuring experiment reproducibility and also traceability.
- Collaboration tools for sharing and discussing results: Pachyderm offers collaboration tools for sharing and discussing experiment results, fostering team communication.
Model Metadata Storage:
- Centralized repository for all model-related information: Pachyderm acts as a centralized repository for storing comprehensive model-related information, promoting organization and also easy access.
- Metadata schema for storing key attributes of models: Pachyderm defines a metadata schema for storing key attributes of models, contributing to effective model information management.
- Versioning and access control: Pachyderm implements versioning and also access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: Pachyderm integrates seamlessly with various ML tools and also platforms, ensuring interoperability.
Management:
- Model registry: Pachyderm provides a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: Pachyderm supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: Pachyderm includes monitoring and also alerting features to track and alert on model performance in production.
- Governance tools: Pachyderm incorporates governance tools for enforcing policies and also managing access to models.
How It Works: Pachyderm excels in ML Tracking by orchestrating data workflows for machine learning endeavors, providing a versatile framework that significantly eases the process of defining and running data pipelines. Leveraging the power of Kubernetes, Pachyderm ensures a scalable and containerized environment for efficient data processing. The platform’s key strength lies in its commitment to versioning and also reproducibility. Pachyderm’s features meticulously track and manage dataset, model, and configuration versions, ensuring data integrity. Enhancing reliability and scalability, Pachyderm strengthens ML Tracking workflows, facilitating effortless reproduction and scaling. Pachyderm is a vital tool for organizations, offering a dependable, scalable solution for managing data complexities. In machine learning projects, Pachyderm empowers teams to reproduce and scale ML Tracking data pipelines effectively.
10. Coiled ML: Open-Source Excellence for Full ML Lifecycle
Coiled Machine Learning (CML) stands out as an exceptional open-source platform tailored for the complete ML lifecycle, including ML Tracking. With meticulous design, it seamlessly handles model creation, training, deployment, and ML Tracking tasks. Its versatility shines through its robust toolkit, particularly in crucial areas like data preprocessing. One of CML’s standout features is its cloud-agnostic framework, guaranteeing smooth execution of ML projects across various platforms, alongside comprehensive ML Tracking capabilities.
Key Capabilities of CML (Coiled Machine Learning):
Experiment Tracking:
- Logging and visualization of hyperparameters, metrics, and artifacts: CML enables logging and also visualization of hyperparameters, metrics, and artifacts during experiments.
- Comparison and analysis of different runs: CML supports the comparison and analysis of different experiment runs through its tracking and also visualization tools.
- Versioning and lineage tracking of experiments: CML provides versioning and also lineage tracking features, ensuring experiment reproducibility and traceability.
- Collaboration tools for sharing and discussing results: CML offers collaboration tools for sharing and also discussing experiment results, fostering team communication.
Model Metadata Storage:
- Centralized repository for all model-related information: CML acts as a centralized repository for storing comprehensive model-related information, promoting organization and also easy access.
- Metadata schema for storing key attributes of models: CML defines a metadata schema for storing key attributes of models, contributing to effective model information management.
- Versioning and access control: CML implements versioning and also access control mechanisms to manage different model versions securely.
- Integration with other ML tools and platforms: CML integrates seamlessly with various ML tools and also platforms, ensuring interoperability.
Management:
- Model registry: CML provides a model registry for registering, tagging, and also searching models, simplifying model management.
- Deployment pipelines: CML supports deployment pipelines, streamlining the deployment of models to production environments.
- Monitoring and alerting: CML includes monitoring and also alerting features to track and alert on model performance in production.
- Governance tools: CML incorporates governance tools for enforcing policies and also managing access to models.
How It Works: In the domain of machine learning, ML Tracking acts as a catalyst, simplifying the entire process through its comprehensive platform. Starting with data preprocessing, ML Tracking facilitates efficient transformation and preparation of datasets for model training. Progressing further, it seamlessly incorporates model training, empowering users to develop and refine models effortlessly. Utilizing a cloud-agnostic framework, ML Tracking offers unmatched flexibility, allowing ML projects to operate seamlessly on diverse platforms without limitations. This adaptability is especially beneficial for teams operating in dynamic environments.
Frequently Asked Questions
What is ML tracking?
ML tracking involves systematically recording and managing metadata associated with machine learning experiments, including data, models, parameters, and results, to ensure reproducibility and transparency in the development process.
What is ML experiment tracking?
ML experiment tracking is the practice of logging and organizing all aspects of machine learning experiments, such as hyperparameters, metrics, and code versions, to facilitate comparison, replication, and optimization of model performance across different trials.
What is ML model monitoring?
ML model monitoring is the continuous observation and evaluation of deployed machine learning models in production to detect drift, anomalies, or performance degradation, enabling timely intervention and maintenance to uphold model reliability and effectiveness.
What is the difference between MLflow and Comet?
MLflow and Comet are both platforms for managing machine learning experiments and projects, but they differ in their specific features and focus. MLflow provides a comprehensive suite of tools for experiment tracking, model management, and deployment, while Comet emphasizes collaboration, visualization, and experimentation with a focus on simplicity and ease of use.
How do you keep track of experiments machine learning?
Experiment tracking in machine learning involves using dedicated tools and platforms such as MLflow, Comet, or custom solutions to systematically record and organize metadata related to experiments, including hyperparameters, metrics, and code versions. This allows for efficient comparison, replication, and optimization of machine learning models.






