

In the digital age, the volume of textual data generated daily is enormous. With the growing importance of big data analytics, text clustering has become an indispensable technique to process and analyze large amounts of text data. Text clustering is a method of grouping similar documents, based on the content of the text. It is a type of unsupervised learning that does not require any prior knowledge about the data. In this article, we will provide an ultimate guide for text clustering, covering its types, applications, and future.
What is Text Clustering?
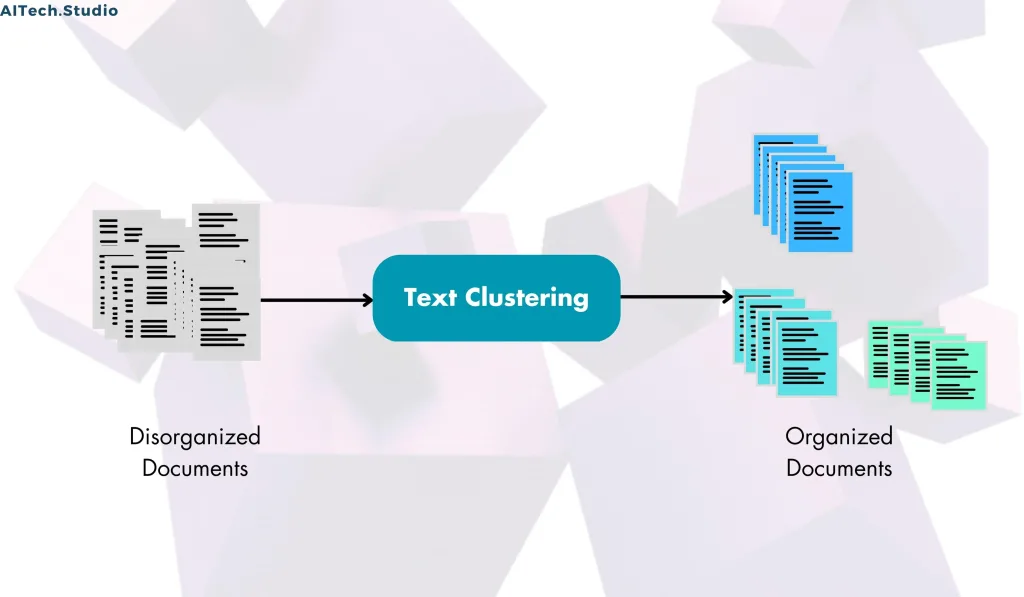
Text clustering also referred to as document clustering or text segmentation, is a fundamental concept in natural language processing (NLP) that falls under the umbrella of unsupervised learning. The primary goal of text clustering is to organize a collection of documents into groups, or clusters, based on the similarity of their content. By doing so, text clustering helps uncover underlying patterns and structures within the data, providing valuable insights into the relationships between documents, topics, and themes.
At its core, text clustering involves applying clustering algorithms to a corpus of text data. These algorithms analyze the textual content of documents and group together those that exhibit similar characteristics or themes. The similarity between documents is typically determined based on various features, such as word frequency, word co-occurrence, or semantic similarity.
One common approach to text clustering is the use of vector space models, where documents are represented as numerical vectors in a high-dimensional space. Clustering algorithms then operate on these vector representations to partition the documents into clusters. Examples of clustering algorithms commonly used in text clustering include K-means, hierarchical clustering, and DBSCAN.
Once the clustering process is complete, each document is assigned to a cluster based on its similarity to other documents in that cluster. This allows for the exploration and analysis of the resulting clusters to gain insights into the underlying structure of the text data. Text clustering can be applied in various domains, including information retrieval, text summarization, and topic modeling, to aid in tasks such as document organization, recommendation systems, and content analysis.
In summary, text clustering is a powerful technique in NLP that facilitates the automatic organization of text data into meaningful groups, enabling researchers and practitioners to extract valuable knowledge and insights from large collections of documents.
Types of Text Clustering
There are several types of text clustering algorithms available, each with its own strengths and weaknesses. In this section, we will discuss some of the most popular text clustering algorithms.
- Hierarchical Clustering
- Hierarchical clustering is a type of clustering algorithm that groups similar documents into a tree-like structure.
- We combine the clusters until they encompass all the documents into a single cluster. Hierarchical clustering is a useful technique for exploring the structure of the data.
- K-means Clustering
- K-means clustering is a popular clustering algorithm that groups similar documents into a pre-defined number of clusters. The algorithm starts by randomly selecting k centroids, where k is the number of clusters.
- Latent Dirichlet Allocation (LDA)
- Latent Dirichlet Allocation (LDA) models use probabilistic modeling for topic modeling. Furthermore, LDA assumes that each document is a mixture of topics, and concomitantly, each topic is a distribution over words.
- Agglomerative Hierarchical Clustering
- Agglomerative Hierarchical Clustering is a type of clustering algorithm that groups similar documents into a hierarchy of clusters.
- DBSCAN
- DBSCAN is a density-based clustering algorithm that groups similar documents based on their density.
- DBSCAN works by identifying dense regions of data and grouping them.
- Mean Shift Clustering
- Mean Shift Clustering is a non-parametric clustering algorithm that groups similar documents based on their local maxima.
- Fuzzy Clustering
- Fuzzy Clustering is a type of clustering algorithm that allows for overlapping clusters.
- Unlike traditional clustering algorithms, which assign each document to a single cluster, Fuzzy Clustering assigns each document to multiple clusters with different degrees of membership.
- Spectral Clustering
- Spectral Clustering is a type of clustering algorithm that uses the eigenvalues and eigenvectors of the data matrix to group similar documents.
Key Features of Text Clustering
Text clustering has several key features that make it a powerful tool for analyzing textual data. Additionally, these features include similarity measures, clustering algorithms, evaluation metrics, preprocessing techniques, and visualization techniques.
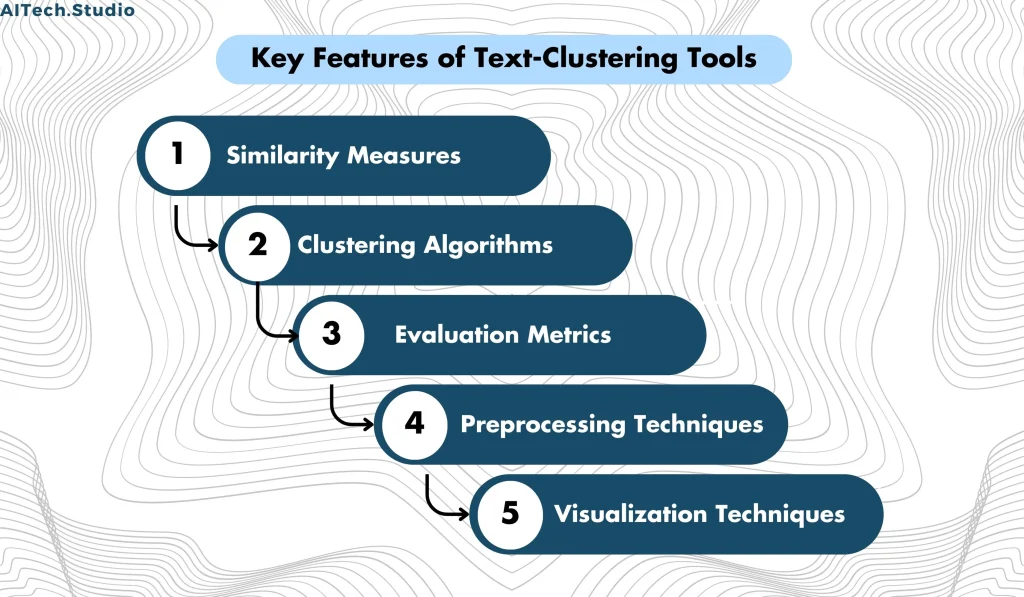
- Similarity Measures
- One uses similarity measures to determine how similar two documents are. In text clustering, we use several similarity measures, including cosine similarity, Jaccard similarity, and Euclidean distance. Moreover, text clustering commonly utilizes cosine similarity as one of its most popular similarity measures.
- Clustering Algorithms
- There are several clustering algorithms used in text clustering, including k-means, hierarchical clustering, and density-based clustering. K-means is a popular algorithm used in text clustering, and it is a centroid-based clustering algorithm.
- Evaluation Metrics
- Evaluation metrics are used to evaluate the performance of algorithms. Additionally, the silhouette score is often employed as the primary evaluation metric in text clustering. Furthermore, this score serves as a measure of how effectively the documents are grouped.
- Preprocessing Techniques
- Preprocessing techniques are used to clean and preprocess textual data before clustering. Preprocessing techniques include tokenization, stop word removal, stemming, and lemmatization.
- Visualization Techniques
- Visualization techniques are used to visualize the results of text clustering. Moreover, visualization techniques include scatter plots, dendrograms, and word clouds.
Steps involved in Text Clustering in NLP
Here are some of the steps involved:
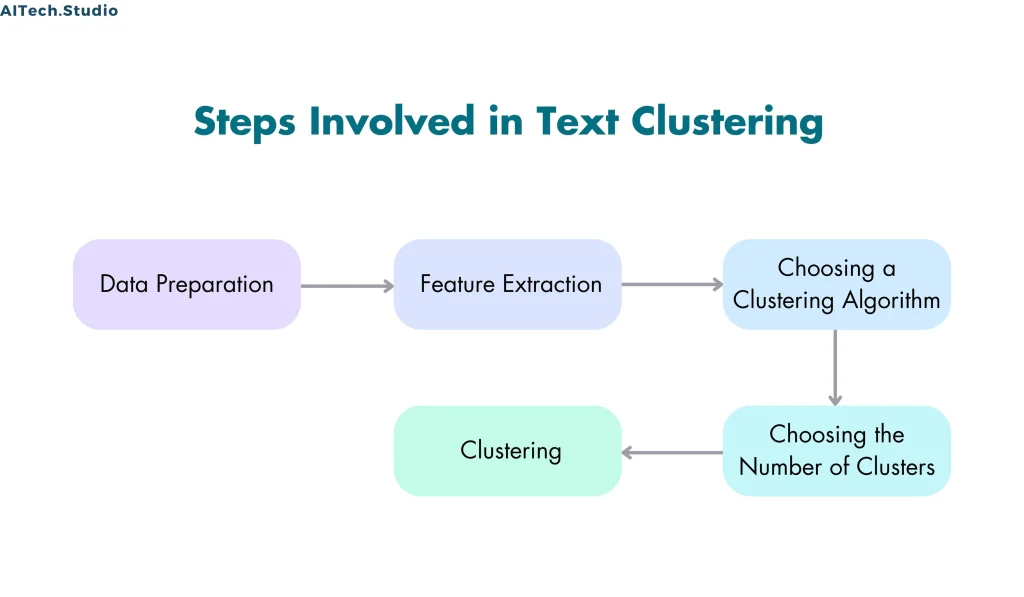
- Step 1: Data Preparation
- The first step in text clustering is to prepare the data. Furthermore, this entails the cleaning and preprocessing of the text data to eliminate unwanted characters, stopwords, and punctuation marks.
- The text data is then converted into a numerical format that can be used for analysis.
- Step 2: Feature Extraction
- The next step is to extract features from the text data. This involves converting the text into a set of numerical features that can be used for clustering.
- There are many different feature extraction techniques available, such as bag-of-words, TF-IDF, and word embeddings.
- Step 3: Choosing a Clustering Algorithm
- Once the features have been extracted, the next step is to choose a clustering algorithm. There are many different clustering algorithms available, such as K-Means, Hierarchical Clustering, and DBSCAN.
- Step 4: Choosing the Number of Clusters
- The next step is to choose the number of clusters. Furthermore, this critical step in text clustering not only determines the final output but also plays a pivotal role in the process.
- There are many different methods available for choosing the number of clusters, such as the elbow method, silhouette score, and gap statistic.
- Step 5: Clustering
- The final step is to perform the clustering. Furthermore, this entails employing the selected clustering algorithm to the feature matrix and subsequently categorizing the documents into clusters.
Products of Text Clustering in Natural Language Processing
- Lexalytics
- Lexalytics is a natural language processing (NLP) and text analytics platform that provides a suite of tools for analyzing text data such as customer feedback, social media posts, and news articles.
- It offers pre-built machine learning models for tasks such as sentiment analysis, entity recognition, and summarization. Lexalytics also provides a sentiment lexicon that allows users to create custom models for sentiment analysis.
- Datumbox
- Datumbox is a machine learning platform that provides a suite of tools for text analysis and predictive analytics. It allows businesses to analyze data from various sources such as social media, customer feedback, and online reviews.
- Datumbox provides pre-built machine-learning models for tasks such as sentiment analysis, topic classification, spam detection, and keyword extraction.
- MonkeyLearn
- MonkeyLearn is a cloud-based text analysis platform that offers a range of natural language processing (NLP) tools and machine learning models for businesses.
- Additionally, its drag-and-drop interface allows users to easily create custom text analysis models without needing coding skills.
- Aylien
- Aylien is a text analysis platform that provides natural language processing (NLP) and machine learning solutions for businesses. It offers a range of tools and APIs for analyzing text data such as news articles, social media posts, and customer feedback.
- It is widely used in industries such as media, finance, and healthcare for tasks such as media monitoring, risk analysis, and customer feedback analysis.
- Know more
- Microsoft Azure Text Analytics
- Microsoft Azure Text Analytics is a natural language processing (NLP) service provided by Microsoft Azure, a cloud computing platform.
- It allows users to analyze and gain insights from unstructured text data such as customer feedback, social media posts, and documents.
- Know more
Applications
It has numerous applications in various fields such as marketing, social media analysis, and healthcare. Furthermore, some of the common applications of text clustering are:
- Document Organization: Organizing large collections of documents based on their content similarity is possible using text clustering. Additionally, this is useful for document management systems and search engines.
- Topic Modeling: One can use text clustering to discover the underlying topics in a large corpus of text. Furthermore, this is useful for understanding the themes and trends in a given domain.
- Sentiment Analysis: Text clustering can identify the sentiment of the text. Additionally, this is useful for social media analysis and customer feedback analysis.
- Recommendation Systems: Furthermore, employing text clustering enables us to suggest comparable products or services, taking into account their content similarity. This feature proves to be invaluable in the realm of e-commerce and online advertising.
Future
Text clustering in NLP is a rapidly evolving field with numerous challenges and opportunities. The future of text clustering is likely to focus on the following areas:
- Real-time Text Clustering
- Real-time text clustering is becoming increasingly important for applications such as social media analysis and customer feedback analysis.
- The future of text clustering is likely to focus on developing more efficient and scalable algorithms for real-time text clustering.
- Integration with Deep Learning
- Deep learning techniques such as neural networks and convolutional neural networks have shown promising results in text classification and clustering.
- The future of this is likely to focus on integrating deep learning techniques with traditional clustering algorithms to improve performance and accuracy.
- Handling Big Data
- With the exponential growth of data, These algorithms need to be able to handle big data efficiently.
- Furthermore, the future of text clustering is likely to focus on developing algorithms that can handle massive datasets in a distributed computing environment.
- Domain-specific Text Clustering in NLP
- Domain-specific text clustering is becoming increasingly important for applications such as healthcare and legal document analysis.
- In addition, we expect that the future of text clustering will focus on developing domain-specific clustering algorithms that can handle the unique characteristics of each domain.
Conclusion
Text clustering is a powerful technique for analyzing and understanding large collections of text. In this article, we have discussed the different types of clustering algorithms used in text clustering, their strengths and weaknesses, and their applications in various fields. We have also discussed the future of text clustering and the challenges and opportunities that lie ahead. With the increasing importance of text data in various domains, it is likely to become an essential tool for data analysis and decision-making.






