

In the years since they were first introduced in the mid-20th century speech recognition and synthesis have advanced significantly. These technologies have become increasingly popular in times of being utilized in areas ranging from virtual assistants to automated phone systems. This article aims to explore the core concepts of speech recognition and synthesis highlighting their importance and the obstacles they present.
Speech recognition involves converting spoken words into text enabling machines to understand and respond to speech. On the other hand speech synthesis entails creating speech from written text allowing devices to communicate naturally with humans. Both these technologies play roles in enhancing human-computer interaction and driving progress in fields such as natural language processing and user interfaces.
The significance of this cannot be underestimated in today’s technology-driven world. They empower users to interact with devices improving accessibility and convenience. From voice-activated assistants like Siri and Alexa to customer service bots these technologies have transformed how we engage with digital tools.
Despite their advancements, challenges persist for speech recognition and synthesis. Issues, like interpreting accents dealing with background noise effectively, and maintaining a natural tone remain ongoing hurdles. Moreover, the ethical aspects of maintaining privacy and security, in voice-activated systems pose dilemmas.
In summary despite the progress in speech recognition and synthesis, there is still a road ahead. As these technologies advance, overcoming obstacles and enhancing functionalities their influence on society will expand, transforming our communication methods and interactions, with technology.

What is Speech Recognition and Synthesis?
These are two closely related technologies that enable machines to interpret and produce human speech. It is the process of converting spoken words into text, while speech synthesis involves generating artificial speech from written text.
Furthermore, advances in machine learning and artificial intelligence over the years have made it possible to create increasingly accurate and natural-sounding speech recognition and synthesis systems. These technologies have many applications in a wide range of fields, including healthcare, education, and entertainment.
How Speech Recognition Works?
Speech synthesis technology works by generating artificial speech from written text. The process involves several steps:
- Text Analysis
- The system analyzes the written text and identifies the various phonemes and words that need to be synthesized.
- Phoneme Generation
- Furthermore, the system generates a sequence of phonemes that correspond to the written text.
- Speech Synthesis
- Finally, the system uses a text-to-speech (TTS) engine to generate artificial speech from the phoneme sequence.
Modern TTS engines use neural networks to generate natural-sounding speech that closely approximates human speech.
Importance of Speech Recognition and Synthesis
Speech recognition and synthesis have become increasingly important in recent years due to the growth of mobile and smart home devices. These technologies have made it possible to interact with machines more naturally and intuitively, enabling new applications such as virtual assistants, voice-controlled devices, and automated phone systems.
Speech recognition and synthesis also have important applications in healthcare and education. For instance, one can utilize speech recognition to transcribe medical dictation, and speech synthesis can generate synthetic speech for individuals with speech impairments.
Main Key Features
- Automatic Speech Recognition
- Automatic speech recognition (ASR) refers to the ability of a speech recognition system to automatically transcribe spoken words into text without human intervention. Furthermore, this feature allows users to interact with their devices without having to type or use a mouse.
- Speaker Diarization
- Speaker diarization is the process of identifying individual speakers in a recording. This feature is essential in applications such as call center analytics, where it is important to know who is speaking.
- Language Identification
- Language identification refers to the ability of a speech recognition system to identify the language being spoken. Furthermore, this feature is essential for applications that require the system to work with multiple languages.
- Keyword Spotting
- Keyword spotting is the ability of a speech recognition system to detect specific keywords or phrases in spoken language. This feature is useful in applications such as virtual assistants, where users can activate the system by speaking a specific phrase.
- Noise Reduction
- Noise reduction is the ability of a speech recognition system to filter out background noise and improve the accuracy of the transcription.
- Speech-to-Text Accuracy
- The accuracy of speech recognition systems is essential for their effective use. Factors such as the quality of the audio, the speaker’s accent, and the complexity of the language being spoken affect the accuracy of the transcription.
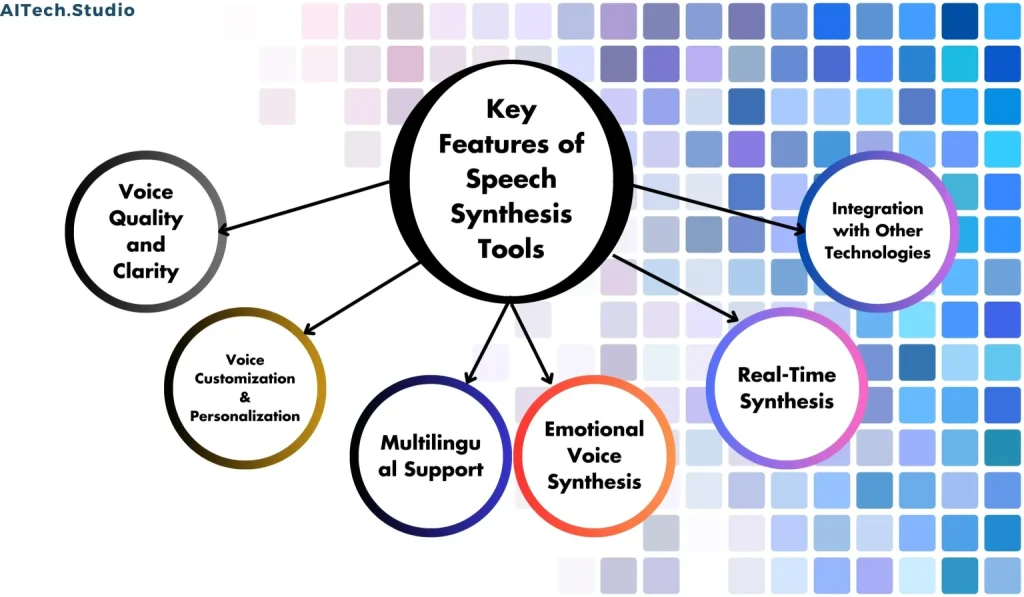
- Voice Quality and Clarity
- One of the most important features of speech synthesis is voice quality and clarity. Modern TTS systems use advanced algorithms and machine learning techniques to create voices that are natural-sounding and easy to understand.
- Voice Customization and Personalization
- Another key feature of speech synthesis is the ability to customize and personalize the voice. This means that users can choose from a variety of voices with different accents, genders, and tones, and even create their custom voice.
Steps Involved in Speech Recognition and Synthesis
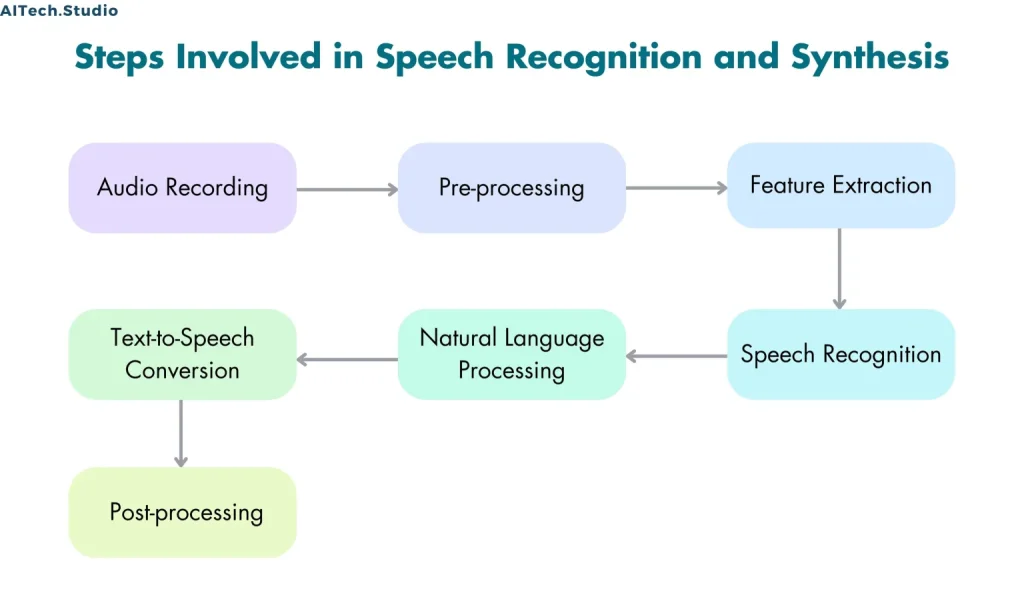
- Step 1: Audio Recording
- The first step in speech recognition and synthesis is audio recording. The quality of the audio recording is essential in determining the accuracy of the speech recognition and synthesis systems.
- Step 2: Pre-processing
- After the audio recording is complete, the pre-processing step begins. Pre-processing involves cleaning and normalizing the audio data to eliminate any background noise or distortion.
- Step 3: Feature Extraction
- Once the audio data is pre-processed, the next step is feature extraction. This step involves identifying the relevant features in the audio data that can be used for speech recognition and synthesis.
- Step 4: Speech Recognition
- It is the process of converting the extracted features into text or machine-readable commands. This step involves using machine learning algorithms to analyze the extracted features and recognize the spoken words.
- Additionally, the accuracy of the speech recognition system is critical in ensuring that the system can understand and respond to spoken words accurately.
- Step 5: Natural Language Processing
- After the spoken words are recognized, the next step is natural language processing. Natural language processing involves analyzing the recognized text to identify the meaning of the spoken words.
- Step 6: Text-to-Speech Conversion
- Additionally, text-to-speech conversion is the process of generating speech from the recognized text. This step involves using a speech synthesis engine to generate speech that sounds natural and human-like.
- The accuracy of the speech synthesis system is critical in ensuring that the generated speech sounds natural and is easy to understand.
- Step 7: Post-processing
- After the speech is generated, the final step is post-processing. Post-processing involves applying various filters and effects to the generated speech to make it sound more natural and human-like.
- Furthermore, this step is critical in ensuring that the generated speech is easy to understand and sounds natural.
The Best Products
- Knowlarity IVR
- Knowlarity’s Interactive Voice Response (IVR) product leverages Natural Language Processing (NLP) in AI to enhance the customer experience.
- Additionally, this product allows customers to communicate with businesses using speech and receive personalized responses based on their queries.
- The NLP technology helps the system understand and interpret natural language, enabling it to provide accurate responses to customers.
- Genesys IVR
- Genesys IVR (Interactive Voice Response) is a product that uses Natural Language Processing (NLP) in AI to enable human-like communication with customers over the phone.
- Additionally, with advanced speech recognition and understanding capabilities, Genesys IVR can interpret and respond to customer requests, inquiries, and commands.
- Otter.ai
- Otter.ai is a natural language processing (NLP) tool that leverages AI to generate transcripts of audio and video recordings in real-time.
- Moreover, its machine learning algorithms are trained on a vast amount of data to accurately transcribe speech and identify speaker identities, making it a powerful tool for note-taking, meeting transcription, and content creation.
- Otter.ai also allows users to search for specific keywords and phrases within transcripts, making it easy to locate and reference important information.
- Fireflies.ai
- Fireflies.ai is an AI-powered virtual assistant that provides automatic transcription, note-taking, and collaboration capabilities for virtual meetings and calls.
- The solution integrates with popular communication platforms such as Zoom, Microsoft Teams, and Google Meet, allowing users to easily capture, organize, and share meeting notes and action items.
- Azure Cognitive Speech Services
- Moreover, Azure Cognitive Speech Services is a cloud-based solution from Microsoft that provides a range of speech and language capabilities to enable businesses to develop voice-enabled applications.
- The solution offers features such as speech-to-text, text-to-speech, and speech translation, which allow developers to integrate voice and language capabilities into their applications and services.
Challenges of Speech Recognition and Synthesis
Despite their many benefits, These technologies still face several challenges. These include:
- Accents and Dialects
- Accents and dialects present challenges, for speech recognition systems often leading to difficulties in recognizing deviations from the standard language model they were initially trained on. These systems face obstacles in understanding the subtleties resulting in errors in comprehension and interpretation. The discrepancies stem from the syntactic characteristics found in various accents and dialects which differ from the parameters of the standardized model. As a result, individuals speaking with standard accents or dialects may encounter frustration and a decline, in system performance impacting the overall effectiveness and user-friendliness of the technology. Resolving this issue necessitates initiatives to improve the inclusivity and flexibility of speech recognition algorithms by incorporating linguistic datasets that can better accommodate the diverse range of global speech patterns and expressions.
- Background Noise
- Background noise presents a challenge, for speech recognition systems making accurate transcription difficult. The presence of sounds can lead to errors in the text by confusion. This interference often comes from sources like machinery, traffic, or nearby conversations. Despite advancements dealing with background noise remains a hurdle in achieving reliable speech-to-text conversion. The complexity lies in distinguishing between intended speech and unwanted noise, necessitating algorithms and filtering techniques. Additionally, environmental factors such as acoustics and distance from the source contribute to the varying impact of background noise. To tackle this issue effectively continuous improvement in signal processing methods and the creation of algorithms that can recognize and reduce background noises influence on transcription accuracy are crucial. Essentially managing background noise plays a role, in improving the efficiency and dependability of speech recognition systems.
- Lack of Context
- In situations where there is no background information speech recognition technology may struggle to recognize words. Take, for example, the word ‘bat’ which could refer to either a winged mammal or a piece of equipment used in sports. In instances, like these, the lack of context clues makes it difficult to accurately interpret the intended message. It becomes crucial to clarify the meaning to improve the system’s precision and user-friendliness. Dealing with contexts poses a challenge in achieving optimal performance underscoring the intricacies of language comprehension, for AI systems.
Conclusion
Speech recognition and synthesis are powerful technologies that have the potential to revolutionize the way we interact with machines. Furthermore, as these technologies continue to evolve, they will become increasingly sophisticated and accurate, enabling new applications and use cases. However, we must overcome many challenges before these technologies can reach their full potential. Furthermore, with ongoing research and development, This will continue to improve and play an increasingly important role in our daily lives.






