

Named Entity Recognition (NER) plays a role, in natural language processing (NLP) by identifying and extracting named entities from text data. These entities include a range of elements like names of individuals organizations, locations, and other entities. The importance of NER lies in its use in text analysis information extraction and various applications that require an automated understanding of data.
This detailed guide aims to provide readers with a grasp of NER covering concepts, advanced methods, and potential future applications. Beginning with the fundamentals of NER we will explain how it works and its core principles. Furthermore, the guide will delve into techniques to offer insights into cutting-edge methods and emerging trends in the field.
Moreover, the discussion will explore NER tools and models such as Spacy NER and AI API while highlighting their features. Through analysis and comparisons, readers will develop a nuanced understanding of the capabilities, limitations, and practical implications of NER frameworks. By providing readers with knowledge and actionable insights this guide aims to empower practitioners and researchers to leverage NER technology to address diverse challenges, in natural language comprehension and information processing.
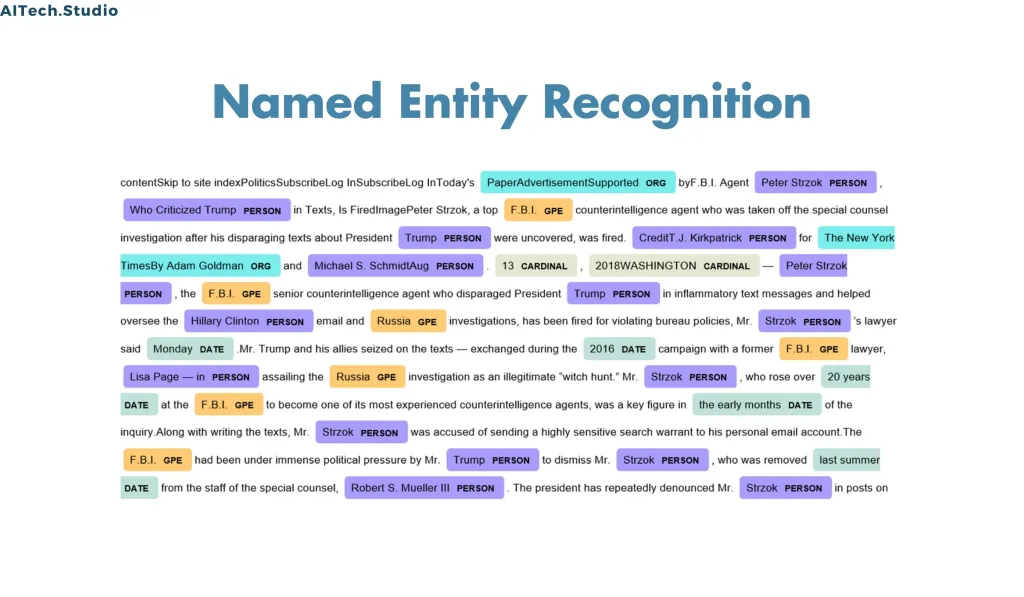
What is Known as Named Entity Recognition?
Named Entity Recognition often abbreviated as NER plays a role, in the field of information extraction. Its main task involves identifying and extracting named entities from text data. These entities can include types such as people, places organizations, products, and events. NER helps analysts unravel the context embedded in data allowing them to extract information necessary for making well-informed decisions.
The importance of NER extends across fields like healthcare, finance, social media, and journalism. In healthcare settings, NER assists in interpreting patient records by pinpointing terms like diseases, medications, and procedures. This streamlines the analysis and decision-making processes in healthcare practices. In finance-related contexts, NER is highly valuable for sifting through reports, news articles, and market analyses to provide insights, on market trends, company performance metrics, and potential risks. Additionally, in social media environments, NER contributes to understanding user interactions conducting sentiment analysis, and Identifying trends that can inform marketing strategies and enhance customer engagement.
In the realm of news articles, Named Entity Recognition (NER) plays a role, in organizing articles identifying entities like people, places, and events. This helps streamline information retrieval and analysis processes. With its uses, NER stands out as a technology that converts unprocessed text data into valuable insights, across various fields. This ultimately enhances decision-making abilities. Promotes innovation.
Types of Named Entities
There are several types of named entities that can be extracted from text data, including:
- Person: Names of people, such as John, Mary, or Barack Obama.
- Organization: Names of companies, institutions, or agencies, such as Apple, Harvard University, or NASA.
- Location: Names of places, such as cities, countries, or landmarks, such as New York, France, or the Eiffel Tower.
- Product: Names of products or services, such as iPhone, Coca-Cola, or Amazon Prime.
- Event: Names of events or activities, such as the Olympics, the Super Bowl, or hiking.
Key Features of Named Entity Recognition
There are several key features that businesses should look for in NER tools:
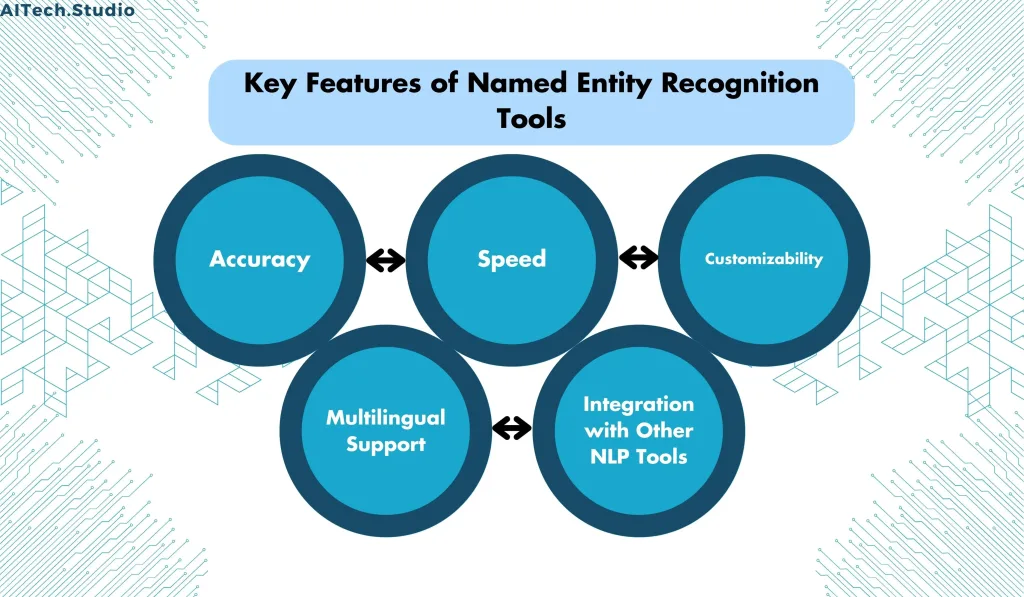
- Accuracy
- Accuracy is a crucial feature of NER tools. Moreover, the tool should possess the capability to accurately identify and classify named entities in text. Furthermore, this accuracy can be quantified through precision, which represents the percentage of correctly identified entities. Additionally, recall measures the percentage of actual entities that are correctly identified.
- Speed
- Speed is also an important factor in NER tools, particularly for businesses that need to process large amounts of text quickly. The tool should be able to process text efficiently and provide results promptly.
- Customizability
- Customizability is another key feature of NER tools. Businesses should be able to customize the tool to their specific needs, such as adding new types of named entities or adjusting the tool’s parameters to improve accuracy.
- Multilingual Support
- Multilingual support is crucial for businesses that operate in multiple languages or countries. Additionally, the tool should be able to identify named entities in multiple languages and provide accurate results.
- Integration with Other NLP Tools
- Integration with other NLP tools is another important feature of NER tools. Businesses may need to use NER in conjunction with other tools, such as sentiment analysis or text classification, and the NER tool should be able to seamlessly integrate with these other tools.
Steps Involved in Named Entity Recognition
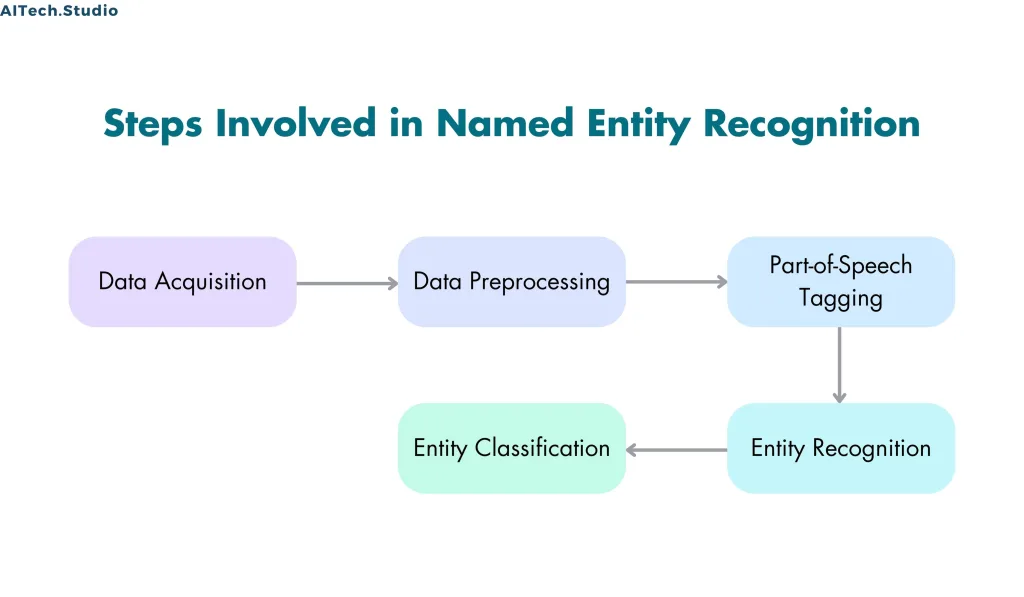
- Step 1: Data Acquisition
- The first step in Named Entity Recognition is acquiring data. The data can be in the form of text documents, web pages, social media posts, or any other unstructured text data. The data should be of good quality, relevant, and suitable for the purpose.
- Step 2: Data Preprocessing
- The next step in Named Entity Recognition is data preprocessing. The goal of this step is to clean and preprocess the data to improve the accuracy of the model. This includes removing stop words, punctuation, and special characters.
- Additionally, the process involves tokenizing the data, which refers to breaking down the text into smaller units such as words, phrases, or sentences.
- Step 3: Part-of-Speech Tagging
- Part-of-speech (POS) tagging is the process of assigning a part of speech to each word in the text. This step is essential in NER because it helps to identify the context of the word and its relation to the other words in the sentence.
- POS tagging can be done using various algorithms such as the Hidden Markov Model (HMM) or Conditional Random Fields (CRF).
- Step 4: Entity Recognition
- The fourth step in NER is entity recognition. This step involves identifying and classifying entities from the text data. This can be done using machine learning algorithms such as Support Vector Machines (SVM), Naive Bayes, or Neural Networks.
- The algorithm is trained on labeled data that contains entities and non-entities.
- Step 5: Entity Classification
- The final step in NER is entity classification. In this step, the identified entities are classified into different categories such as people, organizations, locations, and more.
- The accuracy of the classification depends on the quality of the training data.
Best Named Entity Recognition Tools
- Stanford Named Entity Recognizer (NER):
- The Stanford Named Entity Recognizer (NER) is a tool that effectively identifies and classifies named entities in text data. In other words, it accurately recognizes and categorizes specific objects, people, places, and other entities that possess proper names.
- The NER system uses machine learning algorithms to analyze input text and identify entities such as person names, organizations, locations, and numerical expressions.
- TextRazor:
- TextRazor is a named entity recognition (NER) tool that uses natural language processing (NLP) to identify and extract entities from text. Entities can include people, places, organizations, products, and more.
- TextRazor utilizes a combination of machine learning and rule-based approaches to effectively recognize entities and disambiguate between them.
- Allganize:
- Allganize is an artificial intelligence company that specializes in natural language processing (NLP) technology, particularly named entity recognition (NER). NER is a type of NLP that identifies and extracts important information, such as names, locations, organizations, and dates, from unstructured text data.
- Allganize’s NER technology identifies the entities accurately and efficiently in various languages.
- Repustate
- Repustate is a named entity recognition (NER) tool that uses natural language processing (NLP) to identify and extract named entities from unstructured text.
- Repustate’s NER technology uses machine learning algorithms to analyze the context, syntax, and semantics of text to accurately identify and classify named entities.
- MonkeyLearn
- MonkeyLearn is a cloud-based text analysis platform that uses machine learning to automate the process of Named Entity Recognition (NER). NER is the task of identifying and classifying entities in text, such as people, organizations, locations, and more.
- With MonkeyLearn, users can easily create custom NER models by training them on their own labeled data or by using pre-built models for specific industries or languages.
Future Applications of Named Entity Recognition
Named Entity Recognition has a promising future in various applications, such as:
- Chatbots and virtual assistants: understanding the user’s intent and context based on the named entities mentioned in the user’s query or feedback.
- Recommendation systems: recommending personalized products or services based on the user’s named entities and preferences.
- Knowledge graphs and ontologies: building structured knowledge bases based on the extracted named entities and their relationships.
- Social network analysis: identifying the influential users or groups based on the named entities mentioned in the social media posts or messages.
Challenges and Limitations of Named Entity Recognition
Named Entity Recognition still faces several challenges and limitations, such as:
- Ambiguity and variability of named entities: Named entities often exhibit ambiguity and variability, with multiple meanings, spellings, or contextual dependencies. This complexity results in instances where the same entity can refer to different concepts or entities based on the context in which it is used. Therefore, navigating through named entities requires an understanding of their diverse interpretations and the ability to discern the intended meaning within a given context.
- Noise and errors in text data: Text data often contains errors and noise, like spelling mistakes, short forms, informal language and unconventional wording. These factors present challenges for Named Entity Recognition (NER) systems. Spelling errors can cause discrepancies between identified entities and their actual names while abbreviations and informal language may not match references. Additionally non traditional language usage can puzzle NER models affecting their accuracy in recognizing entities. As a result preprocessing tasks such, as normalization and error correction play a role in improving the performance of NER algorithms to ensure they can accurately extract entities from noisy text data.
- Language and domain dependency: The effectiveness of Named Entity Recognition (NER) models can vary based on the language or field they are used in requiring training or adjustments. Language and field dependencies play a role, in how these models work, with some excelling in particular languages or fields while facing challenges in others. For example, a NER model trained on text might not perform effectively when applied to text in another language due to linguistic nuances and structural variations. Likewise, within the language, the performance of NER models can vary depending on the specific domain of the text, such, as medical, legal, or scientific content. To address these differences developers often have to modify models by incorporating training data or tweaking model structures to better match the target language or field ensuring performance across a range of linguistic and contextual scenarios.
Conclusion
Named Entity Recognition is a powerful and versatile NLP technique that can help us extract valuable information from text data. By identifying and categorizing the named entities, we can better understand the relationships and patterns in the data, and use them for various applications, such as chatbots, recommendation systems, and social network analysis.






